Batch Is Not Enough Anymore. Here's What the Real-Time Stack Actually Looks Like.
There's a moment most data engineers recognize. You've built a solid batch pipeline — clean, tested, running on schedule every night. Then someone from the fraud team asks why the model is missing transactions that happened two hours ago. Or the product team wants personalization that reflects what a user did five minutes ago, not yesterday. Suddenly your nightly job feels like infrastructure from a different era.
Batch pipelines aren't going away. But the ceiling on what they can power has become very obvious, very fast. In financial services, fraud detection built on batch cycles isn't just slow — it's architecturally incapable of stopping fraud while a transaction is still in flight. The window to act closes in milliseconds. The decision needs to happen before the authorization response leaves the network.
This is what's driving the real-time streaming shift in 2026 — not novelty, but the gap between when data is generated and when a system can act on it finally mattering enough to justify the engineering investment.
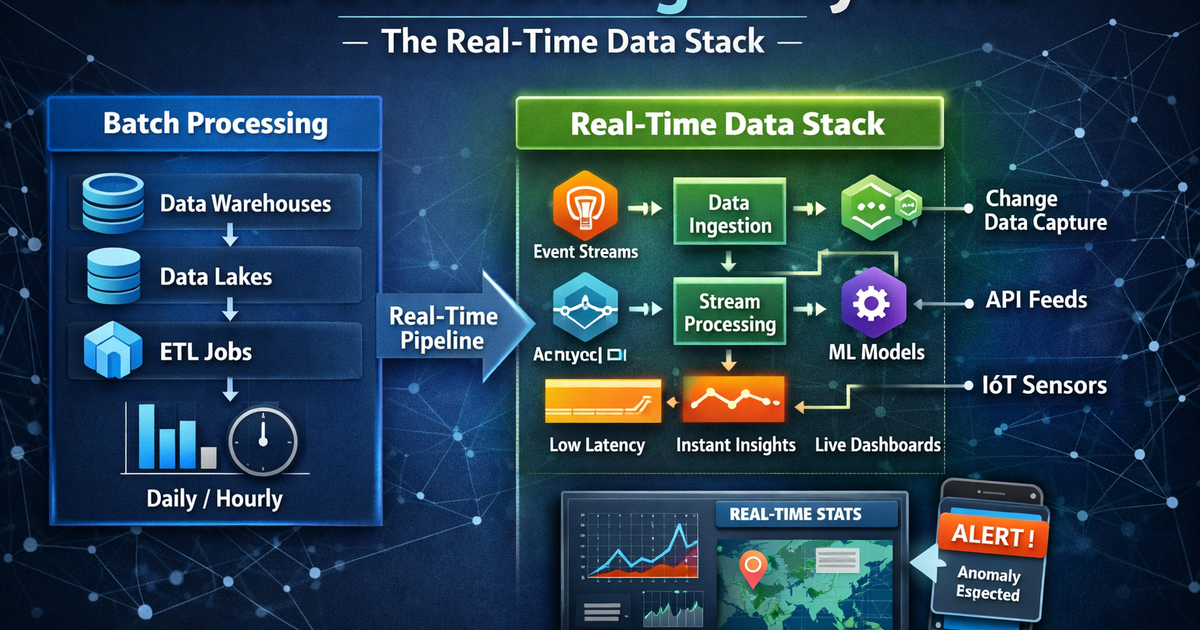
How the stack fits together :
Three tools carry most of the load in modern streaming architectures, and they're not interchangeable — each sits at a different layer.
Kafka is the backbone. Think of it as a high-throughput, durable event log that decouples producers from consumers. Over 150,000 organisations were running Kafka by 2025. It doesn't process data — it moves and buffers it reliably at scale. Producers write events; consumers read them at their own pace. That decoupling is what lets you build streaming systems that don't collapse when one downstream service gets slow.
Flink is where the actual work happens. It sits downstream of Kafka and handles stateful, continuous processing — joins across streams, windowed aggregations, pattern detection, enrichment against reference data. Its exactly-once processing guarantees and native support for event time (as opposed to processing time) make it the right tool when correctness matters, not just throughput. Confluent has already shifted its strategic focus toward Flink as the stream processing standard, effectively conceding that ksqlDB won't carry the workload going forward.
CDC — change data capture — is the piece that closes the loop between your operational databases and your streaming infrastructure. Tools like Debezium watch your Postgres or MySQL transaction logs and emit every insert, update, and delete as a stream event. Instead of querying a database on a schedule and hoping you caught all the changes, you get a continuous, ordered feed of what actually changed and when. Flink can consume this directly, transform it, and write to a lakehouse or warehouse in near real-time. What used to be a nightly sync becomes a pipeline with seconds of latency.
The part nobody mentions in architecture diagrams :
The stack is mature. Kafka, Flink, and CDC are all production-proven. The hard part in 2026 isn't picking the tools — it's managing operational complexity once they're running. Checkpointing strategies, backpressure handling, schema evolution across a live CDC stream, and small-file accumulation in streaming lakehouse writes all require active attention.
The data pipeline tools market is projected to grow from roughly $15 billion in 2025 to $48 billion by 2030. That growth isn't speculative — it reflects how many organisations are in the middle of this migration right now, with real engineers working through real operational problems.
Start with CDC into Kafka if you're still on batch. Get the data moving first. Flink complexity compounds quickly, and there's no point in stateful stream processing if your source data is still arriving in hourly dumps.